So, I do have to start off and say that I have not implemented a Russian Doll Caching solution. This article is highly theoretical and just meant to start a conversation about a possible new way at looking at Caching.
Russian Doll Caching (as I understand it)
Caching is definitely tough. How do you make sure that you are using the most up to date data? Do you cache for a time period? Do you have to track caches manually?
There are a few patterns for Russian Doll Caching which basically allow you to know when nested items have been updated and only update parts of your result as needed.
For this post let's assume that we have a Post with a HasMany relationship to Comments.
Method One - Touching
In my mind this is the least ideal solution for Russian Doll Caching (although in a way it gives some of the largest gains when rendering a chached result). Basically, what happens is that whenever any action happens at the Comment level, you are updating your Post's updated at timestamp. This seems logical and your cache key may look like this:
view/posts/data-Post/{post.id}-{post.updatedAt}
I have two problems with this:
First, let's talk about inefficiency of having to touch parent relationships every time. The easiest way to do this is to pass a touch flag when declaring your relationship in your ORM. But, this means that if you are updating Comments, for each Comment you update, you have to make another query to update the parent Post. You could get around this by making a SQL trigger that updates on the foreign key so that on create or update, copy the Comment timestamp to the parent Post. This solves the query redundancy issue, but you still are running the same logic under the hood of your database.
Secondly, let's look at our index page. It doesn't care about the status of the comments and it's results are completely independent of the related Comments. So we now have broken our whole caching chain for the index page because we don't have the same updated at reference. The other logical step would be to add some sort of hash of the record itself, but then it's a bit messy and we may be doing so much work in cache resolution that we are actually losing efficiency.
Method Two - More Explicit Cache Keys
The other solution to this is to have more explicit cache keys.
Let's say your posts.show rendered result relied on your post and your first three comments.
You could make a cache key that looks a bit like this:
view/posts/data-Post/{post.id}-{post.updatedAt}/Comments/{post.comments[0].id}-{post.comments[0].updatedAt}&{post.comments[1].id}-{post.comments[1].updatedAt}&{post.comments[2].id}-{post.comments[2].updatedAt}
This solves our issue of having to touch parent timestamps. But it does bring up a new problem that plagues both of these two methods: What do you do when only one piece of this data requirement changes? Do you really have to update everything again?
Method Three - True Russian Doll Caching
Let's first start by saying that our template looks like this:
<div class="post">
<h2>{{post.title}}</h2>
<div class="post-body">{{post.compiledContent}}</div>
</div>
<ul class="comments">
{{#each comment in comments}}
<li>
<div class="author">{{comment.authorName}}</div>
<div class="comment-body">{{comment.compiledBody}}</div>
</li>
{{/each}}
</ul>
Wouldn't it be awesome if we could cache our iterations of our each statement (again not going into the actual implementation of that here). Instead of having a cache key reference our entire rendered template, let's make it so that we reference partials for the areas in our loop so our key looks like:
view/posts/data-Post/{post.id}-{post.updatedAt}/partial-Comment/{post.comments[0].id}-{post.comments[0].updatedAt}&{post.comments[1].id}-{post.comments[1].updatedAt}&{post.comments[2].id}-{post.comments[2].updatedAt}
And we have caches of the comment partials with keys
partials/Comment/{comment.id}-{comment.updatedAt}
Now, I'm doing a bit of hand waving over the idea of swapping out a partial which is not trivial. But, it does get us to a good place.
Except that I think we are reinventing the wheel a bit…
This Has Basically Been Done Before
If you are a web developer, what you may not realize is that you likely work with a similar system on a day to day basis. What if instead of this long cache key, I said that this was a md5 of that long string? Does that give you any ideas?
What if instead of templates, I said these were files that changed over time? Is it starting to click?
Basically, I think that we could look at advanced caching in a whole new light if we broke this up to look a bit more like this:
finalCache -- result
\
\- reference to cached underlying data
If we said that the caches could have multiple references to underlying data, then we get to look a bit like a git blob and tree structure (at least in my opinion).
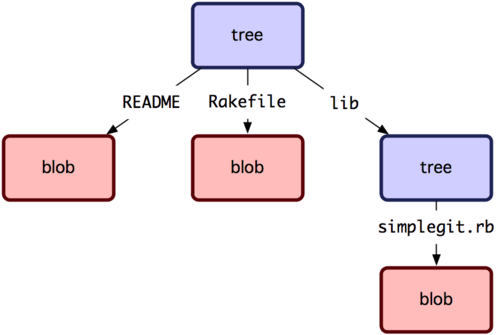
This means a lot more than just leaning on the existing structure of Git. This would mean that you get a ton of things relatively out of the box:
Immutable caching
Ideally caches are already immutable, but since the reference hash in Git hinges on the underlying content and references, then you are forced into immutability
History And Revisioning
Because of the immutability you get the ability to work with older versions of your cache objects and actually revert back and forth between these versions
Manual State Control
I lied a bit earlier when I said that your final cache would directly reference its result. The truth is that the cache tree would look more like Git Commits:
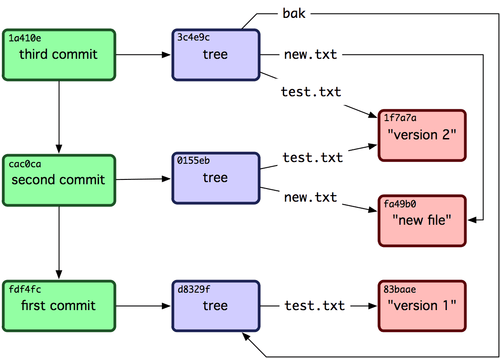
Let's say that we are looking at the caching for something like LeanPub. Our author's working cache could be at the "third commit" stage, while our rendered preview could be at the "second commit", and the published copy available to users is still back on "commit one". In this way our different active versions are similar to branches in git where they reference a committed hash. I lied here too since our branch is a mutable key value pair… Let's say we want to update our preview to the latest cache state just like our author can see: it's a matter of going from referencing "second commit" up to "third commit". No extra rendering, no needing to check state.
Personally, I think it's near ideal! You get infinite nesting of underlying dependencies (and rendered results for each dependency), fast top level cache resolution, multiple states that can be manually referenced if you wanted to go that route, and your own "Way Back Machine" for your cache states!
It seems like I'm not the only one toying around with taking Git principles out of the file system either: Justin Santa Barbara looks at implementing Git fully in Redis!
So… What do you think? Am I just being crazy? Did I go to far with things? Is this even feasible as a caching strategy, nested re-rendering of partial data still seems tough (but possibly not much harder than the current state of Russian Doll Caching)?